
CREATE Salon #3: Tags, tools and transparency
On the day that 30 enormous 17th-century Dutch group portraits were brought together for the first time in the exhibition Hollanders van de Gouden Eeuw, the CREATE Salon took place in the historical Vondelzaal at the Singel. In this illustrious setting we learned about tools for annotating historical Dutch texts, for extracting locations from historical Dutch sources, and for viewing cultural artifacts in their broader context. The three presentations showed how such exciting new research tools can be tailored to research questions posed in the CREATE program, but also serve other purposes. And again, the issue of transparency featured prominently: how to include processes of selection and disambiguation in the interfaces?
 CREATE researcher and computational linguist Dieuwke Hupkes filled us in on the potential and challenge of automatically annotating historical Dutch. She explained how assigning grammatical values, such as noun, verb, adjective, to texts (also known as part-of-speech tagging) is very useful because they help disambiguate so-called ambiguous words. This ambiguity has to do with the fact that words can have different grammatical values – take for instance the example of ‘geweten’ as both a verb and a noun (zij heeft geweten and zij heeft een geweten). Tagging software has been developed for modern languages, also for Dutch, but creating such tools for historical languages has proven difficult. First of all, there were no agreed-upon standardized writing conventions in, for instance, the seventeenth century. And second, resources of historical languages are limited, which makes it difficult to train the software. Still, there are several options to those interested in annotating and lemmatizing historical texts, apart from doing it manually (the Brieven als Buit project). Dieuwke explained how she set about normalizing spelling of historical texts by using rewrite rules (i.e. ick – ik), creating a dictionary generated from a parallel dataset (Statenvertaling 1637 and 1977), and then retraining the tagger using this parallel corpus as well as the Brieven als Buit corpus. Between these methods, she arrived at reasonably high accuracy rates for tagging, but also concluded that normalizing spelling is not sufficient and that variation between domains is quite a substantial problem. What is really needed, she argued, is the development of generic techniques to train taggers for low-resource language like historical Dutch. Still, as Dieuwke pointed out, herself, such tools do not have to strive for perfection; after all, it seems a bit unfair to ask computers to develop skills us humans don’t have.
CREATE researcher and computational linguist Dieuwke Hupkes filled us in on the potential and challenge of automatically annotating historical Dutch. She explained how assigning grammatical values, such as noun, verb, adjective, to texts (also known as part-of-speech tagging) is very useful because they help disambiguate so-called ambiguous words. This ambiguity has to do with the fact that words can have different grammatical values – take for instance the example of ‘geweten’ as both a verb and a noun (zij heeft geweten and zij heeft een geweten). Tagging software has been developed for modern languages, also for Dutch, but creating such tools for historical languages has proven difficult. First of all, there were no agreed-upon standardized writing conventions in, for instance, the seventeenth century. And second, resources of historical languages are limited, which makes it difficult to train the software. Still, there are several options to those interested in annotating and lemmatizing historical texts, apart from doing it manually (the Brieven als Buit project). Dieuwke explained how she set about normalizing spelling of historical texts by using rewrite rules (i.e. ick – ik), creating a dictionary generated from a parallel dataset (Statenvertaling 1637 and 1977), and then retraining the tagger using this parallel corpus as well as the Brieven als Buit corpus. Between these methods, she arrived at reasonably high accuracy rates for tagging, but also concluded that normalizing spelling is not sufficient and that variation between domains is quite a substantial problem. What is really needed, she argued, is the development of generic techniques to train taggers for low-resource language like historical Dutch. Still, as Dieuwke pointed out, herself, such tools do not have to strive for perfection; after all, it seems a bit unfair to ask computers to develop skills us humans don’t have.
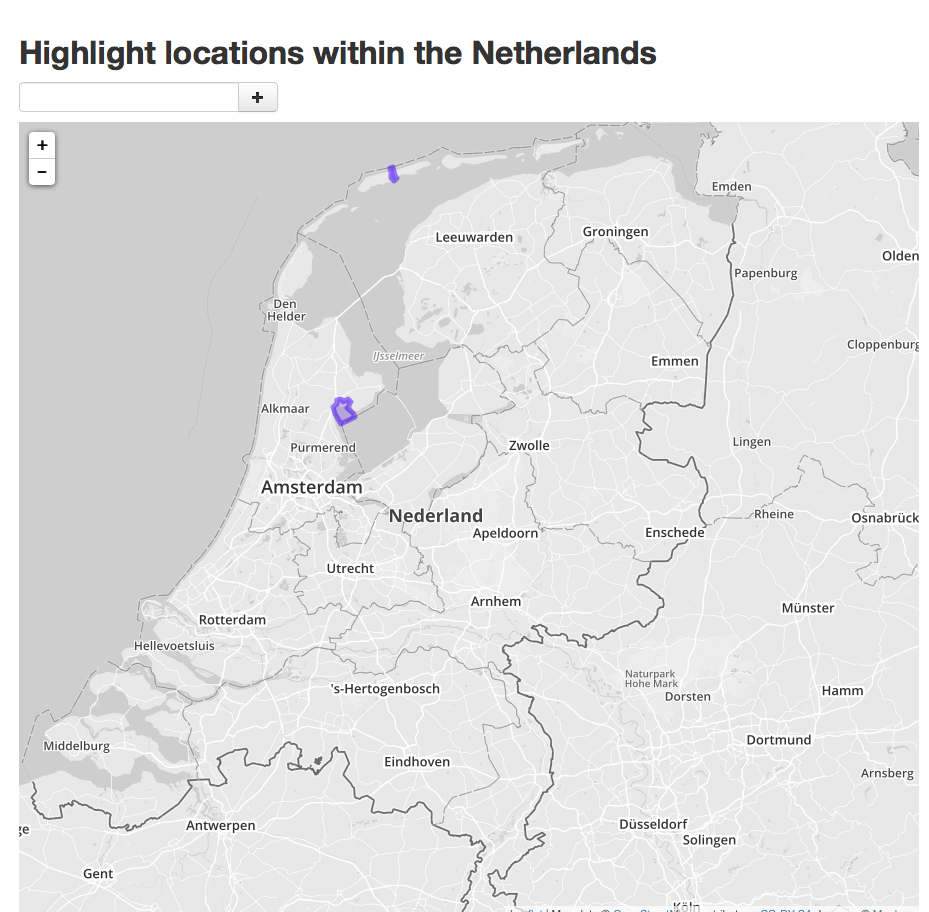 Like Dieuwke, CREATE researcher and philosopher/mathematician/programmer Rosa Merino Claros is also working on a tool to disambiguate information in historical texts. In her case she seeks to extract references to locations from these texts and develop an interface for mapping them. Similar geoparsing tools exist for instance for the UK (Unlock Text and The National Archives) but not yet for the Netherlands. Together with Alex Olieman, who’s working in UvA project ExPoSe: Exploratory Political Search, she’s testing the tool on a training corpus comprising digitally available Dutch Parliamentary Proceedings since 1815. Rosa explained how they’re building a gazetteer based on Open Street Maps data for the Netherlands: a kind of geographical dictionary with names of towns, neighborhoods and streets (both modern and historical). But of course the data will also need to be filtered by disambiguating people and places as well as different locations with the same name (i.e. Hoorn in Noord-Holland and Hoorn on the island of Terschelling). For instance by weighting likely candidates and contexts of reference. As with Dieuwke’s tagging tool, the aim is not to strive for perfection, but for the highest accuracy reasonably possible. Moreover, as became clear in the discussion, another aim should be to show, rather than hide, the processes of disambiguation. In other words, user interfaces should also be able to visualize and communicate what is not known or what is uncertain.
Like Dieuwke, CREATE researcher and philosopher/mathematician/programmer Rosa Merino Claros is also working on a tool to disambiguate information in historical texts. In her case she seeks to extract references to locations from these texts and develop an interface for mapping them. Similar geoparsing tools exist for instance for the UK (Unlock Text and The National Archives) but not yet for the Netherlands. Together with Alex Olieman, who’s working in UvA project ExPoSe: Exploratory Political Search, she’s testing the tool on a training corpus comprising digitally available Dutch Parliamentary Proceedings since 1815. Rosa explained how they’re building a gazetteer based on Open Street Maps data for the Netherlands: a kind of geographical dictionary with names of towns, neighborhoods and streets (both modern and historical). But of course the data will also need to be filtered by disambiguating people and places as well as different locations with the same name (i.e. Hoorn in Noord-Holland and Hoorn on the island of Terschelling). For instance by weighting likely candidates and contexts of reference. As with Dieuwke’s tagging tool, the aim is not to strive for perfection, but for the highest accuracy reasonably possible. Moreover, as became clear in the discussion, another aim should be to show, rather than hide, the processes of disambiguation. In other words, user interfaces should also be able to visualize and communicate what is not known or what is uncertain.
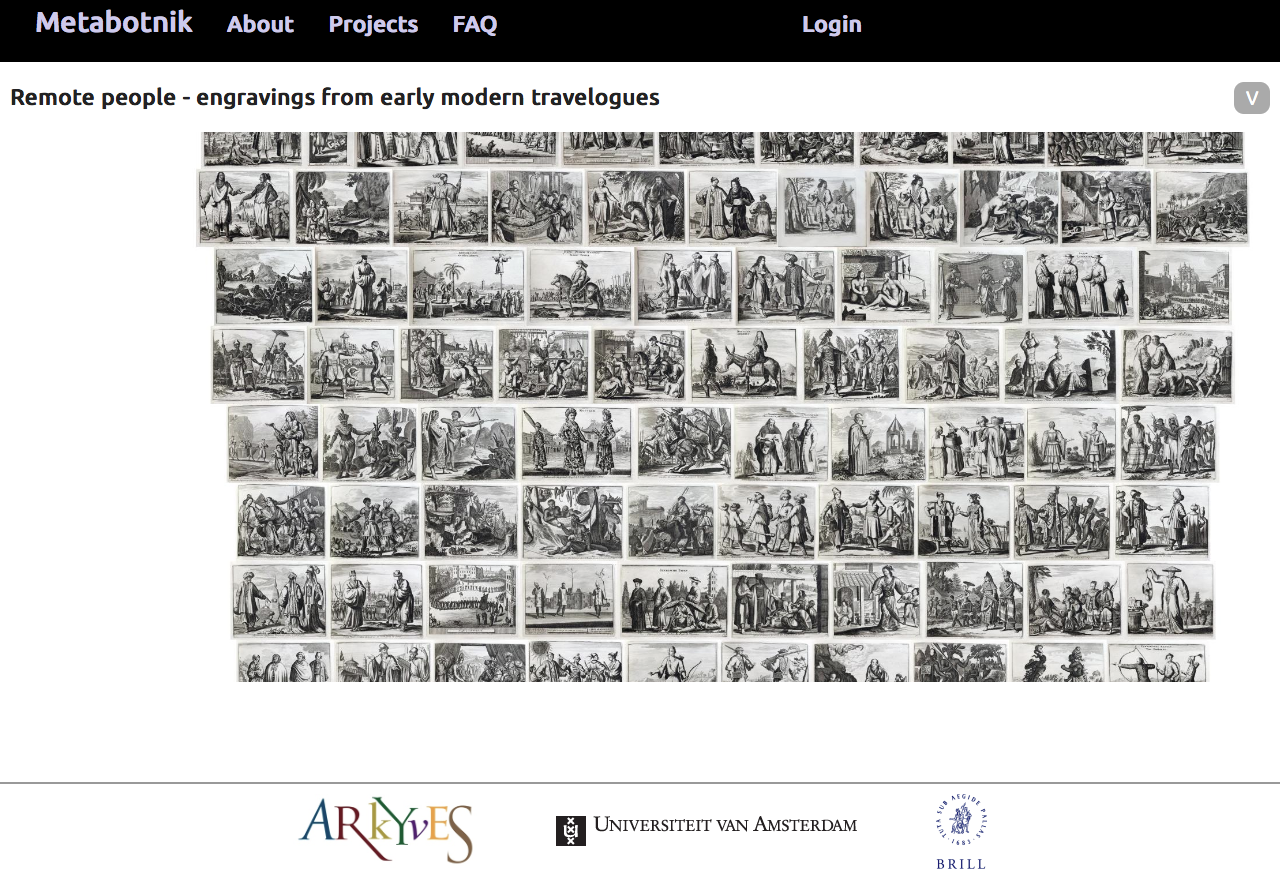 Finally, UvA lecturer and book historian Paul Dijstelberge presented the explorative tool called Metabotnik. The idea for this tool came out of Paul’s Flickr archive of images of historical book initials, ornaments and type, and his tool Geocontexting the printed world, that plots locations of printers and publishers, available at Arkyves. Originally created for a handful of specialists, the Flickr collection turned out to be of great interest to type designers and book designers all around the globe, logging as many as 50,000-60,000 page views per month. Good thing NWO recognized its potential and funded the development of a tool that creates huge zoomable images of, for instance, books or paintings: Metabotnik. Not only can you zoom in on incredibly high-resolution images, but you can also view the images in context: next to other images, structured, for instance, by period, by place, or makers. Such visualization can, for instance, help you trace stylistic innovation across time and space, identify painters or printers, or identify networks and collaborations. Moreover, soon it will also be possible to include metadata and links to other sites and interfaces (Arkyves, Iconclass, Ecartico,…). And, the great thing is that everyone with a Dropbox account can use Metabotnik, so feel fry to give it a try! For instance by collecting images of the Dutch group portraits in your dropbox folder and linking it to Metabotnik, before or after you visit the Hermitage in person?
Finally, UvA lecturer and book historian Paul Dijstelberge presented the explorative tool called Metabotnik. The idea for this tool came out of Paul’s Flickr archive of images of historical book initials, ornaments and type, and his tool Geocontexting the printed world, that plots locations of printers and publishers, available at Arkyves. Originally created for a handful of specialists, the Flickr collection turned out to be of great interest to type designers and book designers all around the globe, logging as many as 50,000-60,000 page views per month. Good thing NWO recognized its potential and funded the development of a tool that creates huge zoomable images of, for instance, books or paintings: Metabotnik. Not only can you zoom in on incredibly high-resolution images, but you can also view the images in context: next to other images, structured, for instance, by period, by place, or makers. Such visualization can, for instance, help you trace stylistic innovation across time and space, identify painters or printers, or identify networks and collaborations. Moreover, soon it will also be possible to include metadata and links to other sites and interfaces (Arkyves, Iconclass, Ecartico,…). And, the great thing is that everyone with a Dropbox account can use Metabotnik, so feel fry to give it a try! For instance by collecting images of the Dutch group portraits in your dropbox folder and linking it to Metabotnik, before or after you visit the Hermitage in person?